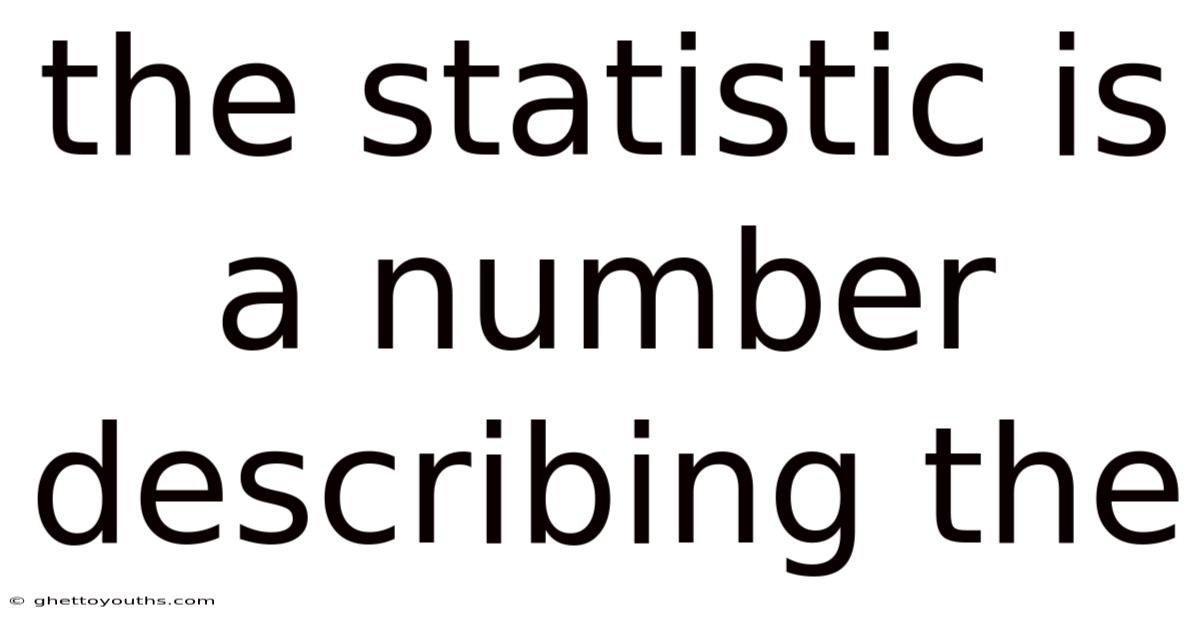
In a world overflowing with data, understanding the language of that data is very important. Still, statistics are the bedrock of evidence-based decision-making, scientific discovery, and even everyday insights. On the flip side, at its core, **a statistic is a number describing a characteristic of a sample. ** But that definition, while technically accurate, barely scratches the surface of its power and utility. And that language often speaks through statistics. From predicting consumer behavior to tracking disease outbreaks, from optimizing marketing campaigns to understanding climate change, statistics provide the crucial lens through which we interpret the world around us That's the whole idea..
The beauty of a statistic lies in its ability to condense complex information into a digestible form. Now, imagine trying to make sense of thousands of individual survey responses without any summarization. Statistics provide us with tools to organize, analyze, and interpret this raw data, allowing us to extract meaningful patterns and insights. It would be overwhelming! Whether it's the average income of a population, the percentage of voters who support a particular candidate, or the correlation between smoking and lung cancer, statistics offer a concise and quantifiable way to describe and understand phenomena.
Introduction
Statistics is more than just crunching numbers; it's a powerful science that provides a framework for understanding the world around us. It enables us to make informed decisions, draw meaningful conclusions, and solve complex problems using data. This full breakdown will look at the core concepts of statistics, exploring its various facets and applications That's the whole idea..
Statistics are numbers that summarize aspects of a sample. Day to day, this idea is foundational to the entire field. Statistics, unlike parameters (which describe populations), are estimates based on incomplete information. This difference is important because it highlights both the power and the limitations of statistical inference Turns out it matters..
Comprehensive Overview
Let's break down the definition: "a statistic is a number describing a characteristic of a sample."
- Number: This seems obvious, but it's important. Statistics are quantifiable. They provide a numerical value that represents some aspect of the data. This allows for objective analysis and comparison.
- Describing: The statistic summarizes information. It takes a collection of data points and condenses it into a single, meaningful value.
- Characteristic: This refers to the specific attribute or feature being measured. It could be anything from the average height of students in a class to the proportion of defective products in a manufacturing batch.
- Sample: This is a crucial concept. A sample is a subset of a larger population. Because it's often impractical or impossible to collect data from the entire population, we rely on samples to make inferences about the whole.
To truly appreciate the power of statistics, it's essential to understand the different types that exist. Here's a breakdown of some key categories:
-
Descriptive Statistics: These statistics aim to summarize and describe the characteristics of a dataset. They provide a clear and concise overview of the data, allowing us to identify patterns and trends. Common examples include:
- Mean: The average value of a set of numbers.
- Median: The middle value in a sorted dataset.
- Mode: The most frequent value in a dataset.
- Standard Deviation: A measure of the spread or variability of the data around the mean.
- Range: The difference between the highest and lowest values in a dataset.
- Frequency Distributions: Tables or graphs that show how often each value or range of values occurs in a dataset.
Descriptive statistics are used to paint a picture of the data at hand. In practice, imagine a teacher wants to understand how their students performed on a test. They could calculate the average score (mean), the score that appeared most often (mode), and how spread out the scores were (standard deviation) to get a sense of the overall class performance But it adds up..
-
Inferential Statistics: These statistics go beyond simply describing the data; they use sample data to make inferences and generalizations about a larger population. This is where the real power of statistics comes into play. Inferential statistics rely on probability theory to assess the likelihood that the observed patterns in the sample data accurately reflect the true patterns in the population. Common examples include:
- Hypothesis Testing: A formal procedure for testing a claim or hypothesis about a population.
- Confidence Intervals: A range of values that is likely to contain the true population parameter with a certain level of confidence.
- Regression Analysis: A technique for modeling the relationship between two or more variables.
Inferential statistics make it possible to draw conclusions about a larger group based on the information we gather from a smaller subgroup. As an example, a political pollster might survey a sample of voters to predict the outcome of an election. They use inferential statistics to estimate the percentage of all voters who will support each candidate, along with a margin of error to account for the uncertainty inherent in sampling It's one of those things that adds up..
-
Measures of Central Tendency: These statistics describe the "typical" or "average" value in a dataset. The most common measures of central tendency are the mean, median, and mode. Each of these measures has its strengths and weaknesses, and the appropriate choice depends on the nature of the data and the research question Easy to understand, harder to ignore..
- Mean: The most widely used measure of central tendency. It's calculated by summing all the values in a dataset and dividing by the number of values. The mean is sensitive to outliers, meaning that extreme values can disproportionately influence its value.
- Median: The middle value in a sorted dataset. The median is less sensitive to outliers than the mean, making it a more strong measure of central tendency for skewed datasets.
- Mode: The most frequent value in a dataset. The mode is useful for identifying the most common category or value in a dataset.
Consider a real estate agent trying to describe the typical home price in a neighborhood. The mean price might be skewed upwards by a few very expensive homes. In this case, the median price would likely provide a more accurate representation of the typical home price It's one of those things that adds up..
-
Measures of Dispersion: These statistics describe the spread or variability of the data around the central tendency. Common measures of dispersion include the range, variance, and standard deviation. Understanding the dispersion of data is crucial for interpreting the mean or median, as it provides information about the homogeneity or heterogeneity of the data.
- Range: The simplest measure of dispersion, calculated as the difference between the highest and lowest values in a dataset. The range is highly sensitive to outliers.
- Variance: A measure of how far the data points are spread out from the mean. Variance is calculated as the average of the squared differences between each data point and the mean.
- Standard Deviation: The square root of the variance. The standard deviation is a more interpretable measure of dispersion than the variance, as it is expressed in the same units as the original data.
Imagine two classrooms taking the same test. Both classrooms might have the same average score, but one classroom might have a much wider range of scores, indicating that some students performed very well while others struggled. The standard deviation would capture this difference in variability Most people skip this — try not to..
-
Probability Distributions: These mathematical functions describe the probability of different outcomes occurring in a random experiment. Probability distributions are essential for inferential statistics, as they provide the basis for calculating probabilities and making predictions.
- Normal Distribution: A bell-shaped distribution that is commonly used to model many natural phenomena.
- Binomial Distribution: A discrete distribution that describes the probability of a certain number of successes in a fixed number of trials.
- Poisson Distribution: A discrete distribution that describes the probability of a certain number of events occurring in a fixed interval of time or space.
Understanding probability distributions allows us to make predictions about the likelihood of future events. To give you an idea, we can use a binomial distribution to calculate the probability of getting a certain number of heads when flipping a coin multiple times Most people skip this — try not to..
Tren & Perkembangan Terbaru
The field of statistics is constantly evolving, driven by advancements in technology and the increasing availability of data. Here are some of the key trends and developments:
-
Big Data Analytics: The rise of big data has created new opportunities and challenges for statisticians. Big data requires new statistical methods and computational tools to handle the volume, velocity, and variety of data Less friction, more output..
-
Machine Learning: Machine learning algorithms are increasingly used for statistical modeling and prediction. Machine learning can handle complex data and identify patterns that would be difficult or impossible to detect using traditional statistical methods.
-
Causal Inference: Causal inference is a growing area of research that focuses on identifying causal relationships between variables. Causal inference is essential for making informed decisions and designing effective interventions.
-
Bayesian Statistics: Bayesian statistics is a statistical approach that emphasizes the role of prior knowledge and beliefs in statistical inference. Bayesian methods are becoming increasingly popular due to their flexibility and ability to incorporate prior information.
-
Data Visualization: Data visualization is an essential tool for communicating statistical findings to a wider audience. Effective data visualizations can help to clarify complex data and insights Worth keeping that in mind. Took long enough..
The increasing availability of data and the development of new statistical methods are transforming many fields, from medicine to marketing to finance. Statisticians are playing an increasingly important role in helping organizations make sense of data and make informed decisions Most people skip this — try not to..
Tips & Expert Advice
Here are some tips for effectively using and interpreting statistics:
-
Understand the context: Statistics should always be interpreted in the context of the data and the research question. Avoid drawing conclusions based solely on the numbers without considering the underlying assumptions and limitations.
-
Be aware of biases: Statistical analyses can be influenced by biases in the data or in the researcher's assumptions. Be critical of the data and the methods used to analyze it, and consider potential sources of bias.
-
Look for patterns and trends: Statistics are most useful when they reveal patterns and trends in the data. Look for consistent relationships between variables and try to understand the underlying mechanisms that are driving these patterns Simple, but easy to overlook..
-
Communicate effectively: Statistics should be communicated clearly and concisely to a wider audience. Use data visualizations and plain language to explain complex concepts and findings.
-
Don't be afraid to ask questions: Statistics can be confusing and intimidating, but make sure to ask questions and seek clarification when needed. Don't be afraid to challenge assumptions or to point out potential problems with the data or the analysis.
By following these tips, you can become a more effective consumer and user of statistics. Remember that statistics are a powerful tool, but they should be used responsibly and ethically.
FAQ (Frequently Asked Questions)
-
Q: What is the difference between a statistic and a parameter?
- A: A statistic describes a sample, while a parameter describes a population.
-
Q: Why do we use samples instead of populations?
- A: It's often impractical or impossible to collect data from the entire population.
-
Q: What is a margin of error?
- A: A margin of error is a measure of the uncertainty in a sample statistic.
-
Q: What is statistical significance?
- A: Statistical significance indicates that the observed result is unlikely to have occurred by chance.
-
Q: How can statistics be misused?
- A: Statistics can be misused by selectively presenting data, using biased samples, or drawing inappropriate conclusions.
Conclusion
The journey through the world of statistics reveals its profound impact on our understanding of the world. From summarizing sample data to inferring insights about entire populations, statistics empowers us to make informed decisions and work through uncertainty. In practice, remember, a statistic is a number describing a characteristic of a sample – but it's also a window into larger truths and a tool for positive change. As you continue to explore the realm of data, embrace the power of statistics to access new knowledge and shape a more data-driven future Most people skip this — try not to..
How do you plan to use your newfound understanding of statistics in your daily life or professional endeavors? Are you inspired to delve deeper into the field and uncover even more insights?